-
Explain the working of Spark with the help of its architecture.
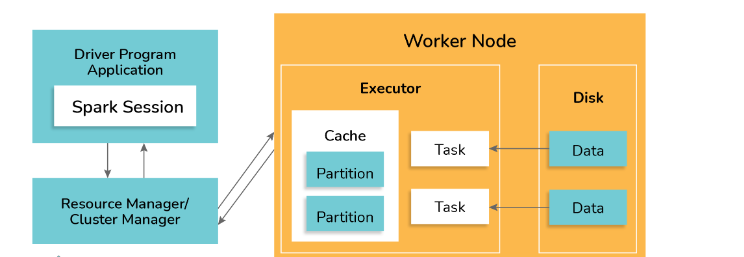
Spark applications operate as independent processes coordinated by the Driver program through a SparkSession object. The cluster manager or resource manager in Spark assigns tasks for executing Spark jobs to worker nodes, following the principle of one task per partition. Iterative algorithms are often used in Spark, where datasets are cached across iterations. Each task applies its set of operations to the dataset within its partition, generating a new partitioned dataset. The results are then sent back to the main driver application for further processing or storage.
Be The First To Comment